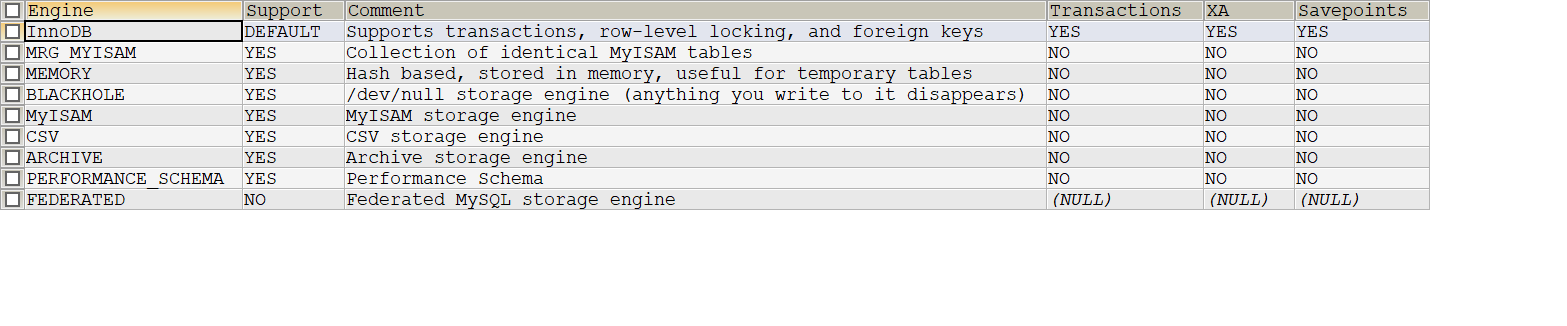
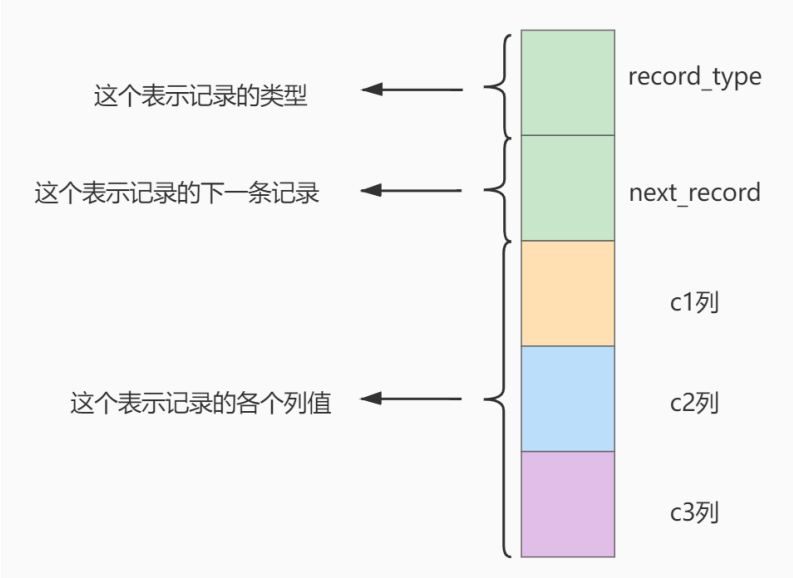
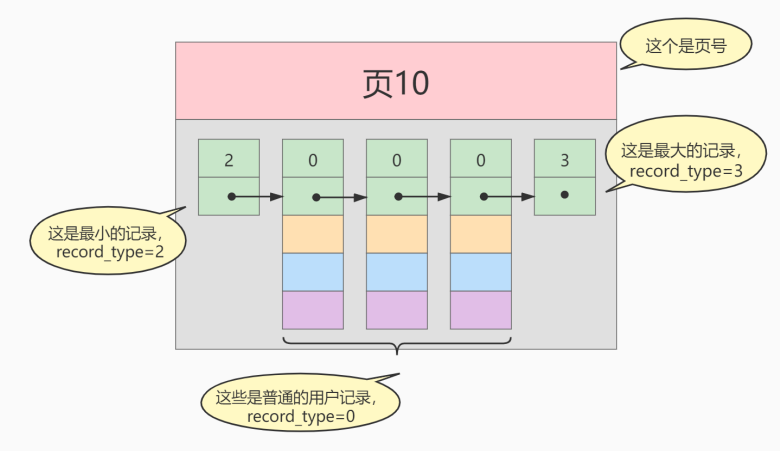
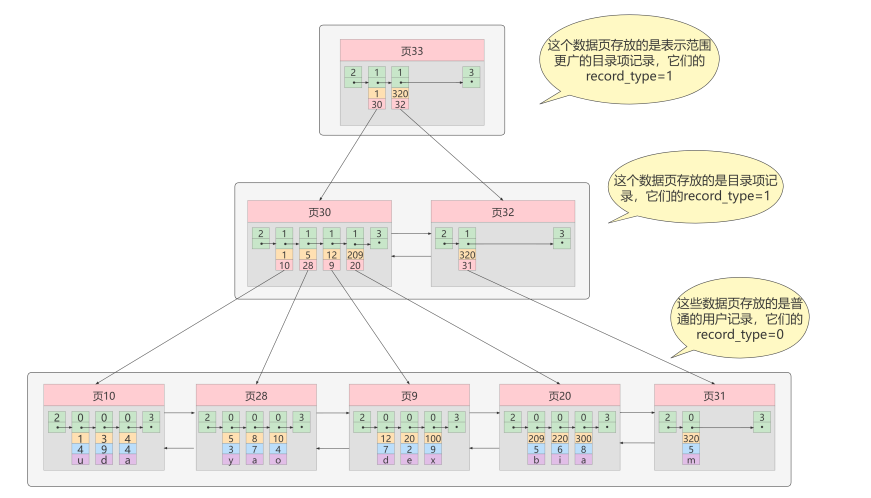
存储引擎是数据库底层的组件,是数据库的核心。 使用存储引擎可以创建、查询、更新、删除数据库。存储引擎可以理解为数据库的操作系统,不同的存储引擎提供的存储方式、索引机制等也不相同,就像 Windows 系统和 Mac 系统一样。在数据库开发时,为了提高 MySQL 的灵活性和高效性,可以根据实际情况来选择存储引擎。
DELIMITER // CREATEFUNCTION rand_string(n INT) RETURNSVARCHAR(255) #该函数会返回一个字符串 BEGIN DECLARE chars_str VARCHAR(100) DEFAULT'abcdefghijklmnopqrstuvwxyzABCDEFJHIJKLMNOPQRSTUVWXYZ'; DECLARE return_str VARCHAR(255) DEFAULT''; DECLARE i INTDEFAULT0; WHILE i < n DO SET return_str =CONCAT(return_str,SUBSTRING(chars_str,FLOOR(1+RAND()*52),1)); SET i = i +1; END WHILE; RETURN return_str; END// DELIMITER ;
SELECT @@log_bin_trust_function_creators;
SETGLOBAL log_bin_trust_function_creators =1;
#函数2:创建随机数函数 DELIMITER // CREATEFUNCTION rand_num (from_num INT ,to_num INT) RETURNSINT(11) BEGIN DECLARE i INTDEFAULT0; SET i =FLOOR(from_num +RAND()*(to_num - from_num+1)) ; RETURN i; END// DELIMITER ;
# 存储过程1:创建插入课程表存储过程 DELIMITER // CREATEPROCEDURE insert_course( max_num INT ) BEGIN DECLARE i INTDEFAULT0; SET autocommit =0; #设置手动提交事务 REPEAT #循环 SET i = i +1; #赋值 INSERTINTO course (course_id, course_name ) VALUES (rand_num(10000,10100),rand_string(6)); UNTIL i = max_num END REPEAT; COMMIT; #提交事务 END// DELIMITER ;
# 存储过程2:创建插入学生信息表存储过程 DELIMITER // CREATEPROCEDURE insert_stu( max_num INT ) BEGIN DECLARE i INTDEFAULT0; SET autocommit =0; #设置手动提交事务 REPEAT #循环 SET i = i +1; #赋值 INSERTINTO student_info (course_id, class_id ,student_id ,NAME ) VALUES (rand_num(10000,10100),rand_num(10000,10200),rand_num(1,200000),rand_string(6)); UNTIL i = max_num END REPEAT; COMMIT; #提交事务 END// DELIMITER ;
#调用存储过程: CALL insert_course(100);
SELECTCOUNT(*) FROM course;
CALL insert_stu(1000000);
SELECTCOUNT(*) FROM student_info;
#2. 哪些情况适合创建索引 #① 字段的数值有唯一性的限制 #② 频繁作为 WHERE 查询条件的字段 #查看当前stduent_info表中的索引 SHOW INDEX FROM student_info; #student_id字段上没有索引的: SELECT course_id, class_id, NAME, create_time, student_id FROM student_info WHERE student_id =123110; #276ms
#给student_id字段添加索引 ALTERTABLE student_info ADD INDEX idx_sid(student_id);
#student_id字段上有索引的: SELECT course_id, class_id, NAME, create_time, student_id FROM student_info WHERE student_id =123110; #43ms
#③ 经常 GROUPBY 和 ORDERBY 的列
#student_id字段上有索引的: SELECT student_id, COUNT(*) AS num FROM student_info GROUPBY student_id LIMIT 100; #41ms
#删除idx_sid索引 DROP INDEX idx_sid ON student_info;
#student_id字段上没有索引的: SELECT student_id, COUNT(*) AS num FROM student_info GROUPBY student_id LIMIT 100; #866ms
#再测试: SHOW INDEX FROM student_info;
#添加单列索引 ALTERTABLE student_info ADD INDEX idx_sid(student_id);
ALTERTABLE student_info ADD INDEX idx_cre_time(create_time);
SELECT student_id, COUNT(*) AS num FROM student_info GROUPBY student_id ORDERBY create_time DESC LIMIT 100; #5.212s
#修改sql_mode
SELECT @@sql_mode;
SET @@sql_mode ='STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_ENGINE_SUBSTITUTION';
#添加联合索引 ALTERTABLE student_info ADD INDEX idx_sid_cre_time(student_id,create_time DESC);
SELECT student_id, COUNT(*) AS num FROM student_info GROUPBY student_id ORDERBY create_time DESC LIMIT 100; #0.257s
#再进一步: ALTERTABLE student_info ADD INDEX idx_cre_time_sid(create_time DESC,student_id);
DROP INDEX idx_sid_cre_time ON student_info;
#会使用idx_sid单列索引而不会使用idx_cre_time_sid索引 SELECT student_id, COUNT(*) AS num FROM student_info GROUPBY student_id ORDERBY create_time DESC LIMIT 100; #3.790s # 总结:创建联合索引的时候,先写GROUPBY字段的,后写ORDERBY字段的
#④ UPDATE、DELETE 的 WHERE 条件列 SHOW INDEX FROM student_info;
UPDATE student_info SET student_id =10002 WHERE NAME ='462eed7ac6e791292a79'; #0.633s
#添加索引 ALTERTABLE student_info ADD INDEX idx_name(NAME);
UPDATE student_info SET student_id =10001 WHERE NAME ='462eed7ac6e791292a79'; #0.001s
SELECT s.course_id, NAME, s.student_id, c.course_name FROM student_info s JOIN course c ON s.course_id = c.course_id WHERE NAME ='462eed7ac6e791292a79'; #0.001s
DROP INDEX idx_name ON student_info;
SELECT s.course_id, NAME, s.student_id, c.course_name FROM student_info s JOIN course c ON s.course_id = c.course_id WHERE NAME ='462eed7ac6e791292a79'; #0.227s
#⑦使用列的类型小的创建索引
#⑧使用字符串前缀创建索引
#⑨ 区分度高(散列性高)的列适合作为索引
#⑩ 使用最频繁的列放到联合索引的左侧 SELECT* FROM student_info WHERE student_id =10013AND course_id =100;
#补充:在多个字段都要创建索引的情况下,联合索引优于单值索引
# 3. 哪些情况不适合创建索引 # ① 在where中使用不到的字段,不要设置索引
# ② 数据量小的表最好不要使用索引
# ③ 有大量重复数据的列上不要建立索引 #结论:当数据重复度大,比如`高于 10% `的时候,也不需要对这个字段使用索引。
#④ 避免对经常更新的表创建过多的索引
#⑤ 不建议用无序的值作为索引
# ⑥ 删除不再使用或者很少使用的索引
# ⑦ 不要定义冗余或重复的索引
7.2哪些情况适合创建索引
1. 字段的数值有唯一性的限制
2.频繁作为 WHERE 查询条件的字段
3.经常 GROUP BY 和 ORDER BY 的列
4.UPDATE、DELETE 的 WHERE 条件列
5.DISTINCT 字段需要创建索引
6.多表 JOIN 连接操作时,创建索引注意事项
连接表的数量尽量不要超过 3 张、 对 WHERE 条件创建索引 、 对用于连接的字段创建索引,并且该字段在多张表中的 类型必须一致